CROW AGENCY — Members of the Crow Tribe from all over the state gathered at Little Big Horn College Friday to celebrate the historic release of a Crow language print dictionary.
“I’m all for revitalizing the Crow language,” said Crow tribal member Velma Pretty On Top Pease.
Hundreds of community members who contributed to the most comprehensive Crow language dictionary ever released were honored at a Friday event.
“Studies have shown that if students know their culture, their language, it develops a strong sense of identity,” said Pretty On Top Pease.
Pretty On Top Pease assisted in the recording and rapid word collection of the dictionary. Crow is her first language, but she says that’s not the case with later generations.
“The next generation, the numbers dropped drastically,” said Pretty On Top Pease.
The dictionary consists of over 11,000 Crow words and will be used as a tool for future generations to ensure the language endures. This project has been in the works for nearly a decade.
“What this means is that the Crow language is one of the best-documented Native languages in North America,” said Dr. Timothy McCleary, co-editor of the Crow dictionary.
McCleary has been in the community for 30 years and knows the language, but he says he’s not fluent.
“The major difference between Crow and English is that Crow is what’s called a tonal language, so much like a number of Asian languages,” said McCleary.
None of this would have been possible without the Crow Language Consortium, a collective of Crow schools, colleges, and educators working to preserve the language.
Cyle Oldelk helped translate Crow words into English for the dictionary. He’s been working on this project since 2015 and Crow was his first language.
“When I was in Head Start, we were told not to speak Crow, and then now it’s to a point where they’re encouraging it. I think it’s really, it’s got to happen for our language to survive,” said Oldelk.
Now, future generations of Crow tribal members will have a resource to keep their culture alive.
Mozilla has added an official translation tool to Firefox that doesn’t rely on cloud processing to do its work, instead performing the machine learning–based process right on your own computer. It’s a huge step forward for a popular service tied strongly to giants like Google and Microsoft.
The translation tool, called Firefox Translations, can be added to your browser here. It will need to download some resources the first time it translates a language, and presumably it may download improved models if needed, but the actual translation work is done by your computer, not in a data center a couple hundred miles away.
This is important not because many people need to translate in their browsers while offline — like a screen door for a submarine, it’s not really a use case that makes sense — but because the goal is to reduce end reliance on cloud providers with ulterior motives for a task that no longer requires their resources.
It’s the result of the E.U.-funded Project Bergamot, which saw Mozilla collaborating with several universities on a set of machine learning tools that would make offline translation possible. Normally this kind of work is done by GPU clusters in data centers, where large language models (gigabytes in size and with billions of parameters) would be deployed to translate a user’s query.
But while the cloud-based tools of Google and Microsoft (not to mention DeepL and other upstart competitors) are accurate and (due to having near-unlimited computing power) quick, there’s a fundamental privacy and security risk to sending your data to a third party to be analyzed and sent back. For some this risk is acceptable, while others would prefer not to involve internet ad giants if they don’t have to.
If I Google Translate the menu at the tapas place, will I start being targeted for sausage promotions? More importantly, if someone is translating immigration or medical papers with known device ID and location, will ICE come knocking? Doing it all offline makes sense for anyone at all worried about the privacy implications of using a cloud provider for translation, whatever the situation.
I quickly tested out the translation quality and found it more than adequate. Here’s a piece of the front page of the Spanish language news outlet El País:
Image Credits: El País
Pretty good! Of course, it translated El País as “The Paris” in the tab title, and there were plenty of other questionable phrasings (though it did translate every | as “Oh, it’s a good thing” — rather hilarious). But very little of that got in the way of understanding the gist.
And ultimately that’s what most machine translation is meant to do: report basic meaning. For any kind of nuance or subtlety, even a large language model may not be able to replicate idiom, so an actual bilingual person is your best bet.
The main limitation is probably a lack of languages. Google Translate supports over a hundred — Firefox Translations does an even dozen: Spanish, Bulgarian, Czech, Estonian, German, Icelandic, Italian, Norwegian Bokmal and Nynorsk, Persian, Portuguese and Russian. That leaves out quite a bit, but remember this is just the first release of a project by a nonprofit and a group of academics — not a marquee product from a multi-billion-dollar globe-spanning internet empire.
In fact, the creators are actively soliciting help by exposing a training pipeline to let “enthusiasts” train new models. And they are also soliciting feedback to improve the existing models. This is a usable product, but not a finished one by a long shot!
Last week, I promised to write something about idioms in dictionaries and on that note finish my discussion of English set phrases (unless there are questions, suggestions, or vociferous cries for more). Where do you find the origin and, if necessary, the meaning of never say die, never mind, and other phrases of this type? Should you look them up under never, say, die, or mind? Will they be there? And who was the first to say those memorable phrases? Nowadays, people search for answers on the Internet, but the Internet does not generate knowledge: it only summarizes the available information and various opinions. We also wonder: Is never say die an idiom? Never mind probably is.
The oldest genres of idioms are proverbs (a friend in need is a friendindeed) and so-called familiar quotations(more in sorrow than in anger), neither of which has been at the center of my interest. The Greeks and espeiclly the Romans produced memorable phrases the moment they began to speak. Life is short, art is long. Good friends cannot be bought. A water drop hollows a stone. As long as I breathe, I have hope. How true! Excellent dictionaries of such phrases (“familiar quotations”) exist, but, as I have noted, not they will concern us today. We are returning to the likes of the phrases I have cited more than once: to kick the bucket, in apple-pie order, to go woolgathering, not room enough to swing a cat, mad as a hatter, and so forth. Dictionaries of idiomatic phrases are many. The best of them explain the meaning of such outwardly incomprehensible locutions, sometimes quote the books in which they occur, and explain their origin if something is known about that subject, but most focus on meaning and usage.
Not everybody goes woolgathering. (Image by M W from Pixabay, public domain)
General (all-purpose) dictionaries like Webster’s and the OED include set phrases as a matter of course, but, though they offer the user the etymology of words (even if all they can say is “origin unknown”) idioms often remain without any historical notes. My prospective dictionary, though a rather thick book, contains slightly more than a thousand idioms (a drop—a pretty heavy drop— in the bucket, or, as they say in German, a drop on a hot stone), but its purpose is to sift through all the existing conjectures about the origin of each item and support, if possible, the most reasonable one. Its main merit is the critique of multifarious conjectures, some of which are excellent, and some are downright stupid. As I said in the previous post, no etymological algebra is needed here. Try to find out whether hatters were ever mad, who tried to swing a cat and failed for want of space, what apple-pie order means, why we should mind our p’s and q’s, and the riddle will be solved.
I’ll begin my rundown on the sources with the most recent one known to me. Allen’s Dictionary of English Phrases (Penguin, 2006; its author is Robert Allen) is comprehensive and reliable. Though etymology was not Allen’s main objective, he never neglected it, and, in discussing conflicting hypotheses, showed excellent judgment. He mined the riches of the OED and many other sources, while I mainly followed journal publications for four centuries and cited dictionaries as an afterthought. (Allen also occasionally used Notes and Queries, my main source of inspiration.) While I am on the letter A, I should mention G. L. Apperson, the author of the book EnglishProverbs and Proverbial Phrases (London: Dent, 1929). Apperson was an outstanding specialist, and his book is a joy to read.
Perhaps the most famous and also the thickest book in this area was written by E. Cobham Brewer. His Dictionary of[Modern] Phrase and Fable (1894, a drastically revised version of the book first published in 1870) is the only one of his many once popular works that has not gone with the wind. A copy of it was on “every gentleman’s desk,” as they used to say at that time. Anyone who sought information about “phrase and fable” consulted Brewer. A learned man, he did one unforgivable thing: he explained the origin of idioms without referring to his sources. Many of the explanations are reasonable, but as many are unacceptable. The latest, severely abridged edition appeared in 2011. The information in even this volume should be treated with caution, but the editors had no choice, because the flavor of the original work had to be preserved.
Brewer’s competitor, but on an incomparably more modest scale, was Eliezer Edwards, the author of Words,Facts, and Phrases: A Dictionary of Curious, Quaint, and Out-of-the Way Matters (London: Chatto and Windus, 1882). Not much in that collection is quaint, and even less is out of the way, but nothing works like an attractive title. The dictionary was much used, but it never enjoyed the popularity of Brewer’s magnum opus. At that time, people appreciated miscellanies containing heterogeneous “nuggets of knowledge.” This book, like Brewer’s, is dogmatic: Edwards gave no references in support of his derivations: he explained the origin of idioms as he saw fit.
Among the reference books published before the Second World War two should be mentioned. 1) AlbertM. Hyamson, A Dictionary of English Phrases…. (London: Routledge, New York: Dutton, 1922.) The corpus is huge, but the etymologies are not always reliable for the same familiar reason: the user rarely knows whether the explanations are the author’s or common knowledge, or borrowed from some of the dictionaries he referred to. The uncritical approach to etymology is the main drawback of this genre. 2) Alfred H. Holt,Phrase Origins: A Study of Familiar Expressions. (New York: Thomas Y. Crowell, 1936.) Despite its title, this work contains numerous entries on individual words. The book can still be recommended because of its cautious approach to the material. Holt used various sources, and when he ventured his own hypotheses, he always said so.
Not every brewer searches for words and phrases. (Image, left: E. Cobham Brewer via Wikimedia Commons; right Beer sommelier at work at Nebraska Brewing Company, via Wikimedia Commons)
An often-used collection is a three-volume book by William and Mary Morris, Dictionary of Word andPhrase Origins. (New York: Harper and Row, 1962-1971.) William Morris was the Editor-in-Chief of the first edition of The AmericanHeritage Dictionary of the English Language, but the dictionary of word and phrase origins can hardly be called a success, because many explanations are unreliable, and the references to the authors’ sources are very few. A more rewarding fruit of teamwork is Dictionary of Idioms and Their Origins by Roger and LinaFlavell (Kyle Cathie, 1992). The origins are explained without reference to the sources, but most of them are acceptable. Last but not least, mention should be made of Charles Earl Funks’s Curious Word Origins, Sayings & Expressions from White Elephant to Song and Dance. (New York: Galahad Books, 1993.) The huge volume (988 pages, with excellent illustrations strewn generously all over the text) includes the author’s three earlier books: AHog on Ice, Heaven to Betsy!, and Horsefeathers. The second part is only about words, but the first and the third deal with idioms. Some entries are quite detailed.
It will be only fair to mention the three collections that were especially often consulted in the past. They are John Ray, A Compleat (sic) Collection of English Proverbs (1678), George Bohn’s (1796-1864), A Handbook of Proverbsby John Ray, a radical reworking of Ray’s pioneering work, and English Proverbs and Proverbial Phrases by W. Carew Hazlitt (1834-1913).
The list at my disposal is very long, and reproducing most or the whole of it might only bore our readers. The fragment presented above gives an adequate idea of the state of the art, and those who are interested in the study of idioms may “make a note of it,” as Captain Cuttle, a memorable character in Dickens’s novel Dombey and Son (1846-1848) used to say. His favorite phrase—”When found, make a note of it”—was chosen as the motto of the British periodical Notes and Queries, which began to appear in 1849 and turned out to be a treasure house of letters on all things under the sun, including the origin of English words and idioms.
Featured image by Dan Parsons via Wikimedia Commons, public domain
Scores for languages when translating from English and back to English again, correlated to how many sample sentences the language has. Toward the right side, higher numbers of example sentences result in better scores. There are outliers, such as English in Cyrillic, which has very few examples but translates well.
Bapna et al., 2022
What do you do after you have collected writing samples for a thousand languages for the purpose of translation, and humans still rate the resulting translations a fail?
Examine the failures, obviously.
And that is the interesting work that Google machine learning scientists related this month in a massive research paper on multi-lingual translation, "Building Machine Translation Systems for the Next Thousand Languages."
"Despite tremendous progress in low-resource machine translation, the number of languages for which widely-available, general-domain MT systems have been built has been limited to around 100, which is a small fraction of the over 7000+ languages that are spoken in the world today," write lead author Ankur Bapna and colleagues.
The paper describes a project to create a data set of over a thousand languages, including so-called low-resource languages, those that have very few documents to use as samples for training machine learning.
Also: DeepMind: Why is AI so good at language? It's something in language itself
While it is easy to collect billions of example sentences for English, and over a hundred million example sentences for Icelandic, for example, the language kalaallisut, spoken by about 56,000 people in Greenland, has fewer than a million, and the Kelantan-Pattani Malay language, spoken by about five million people in Malaysia and Thailand, has fewer than 10,000 example sentences readily available.
To compile a data set for machine translation for such low-resource languages, Bapna and two dozen colleagues first created a tool to scour the Internet and identify texts in low-resource languages. The authors use a number of machine learning techniques to extend a system called LangID, which comprises techniques for identifying whether a Web text belongs to a given language. That is a rather involved process of eliminating false positives.
After scouring the Web with LangID techniques, the the authors were able to assemble "a dataset with corpora for 1503 low-resource languages, ranging in size from one sentence (Mape) to 83 million sentences (Sabah Malay)."
The scientists boiled that list down to 1,057 languages "where we recovered more than 25,000 monolingual sentences (before deduplication)," and combined that group of samples with the much larger data for 83 "high-resource languages" such as English.
Also: AI: The pattern is not in the data, it's in the machine
They then tested their data set by running experiments to translate between the languages in that set. They used various versions of the ubiquitous Transformer neural net for language modeling. In order to test performance of translations, the authors focused on translating to and from English with 38 languages for which they obtained example true translations, including kalaallisut
That's where the most interesting part comes in. The authors asked human reviewers who are native speakers of low-resource languages to rate the quality of translations for 28 languages on a scale of zero to six, , with 0 being "nonsense or wrong language" and 6 perfect."
Also: Facebook open sources tower of Babel, Klingon not supported
The results are not great. Out of 28 languages translated from English, 13 were rated below 4 on the scale in terms of quality of translation. That would imply almost half of the English to target translations were mediocre.
The authors have a fascinating discussion starting on page 23 of what seems to have gone wrong in those translations with weak ratings.
"The biggest takeaway is that automatic metrics overestimate performance on related dialects," they write, meaning, scores the machine assigns to translations, such as the widely used BLEU score, tend to give credit where the neural network is simply translating into a wrong language that is like another language. For example, "Nigerian Pidgin (pcm), a dialect of English, had very high BLEU and CHRF scores, of around 35 and 60 respectively. However, humans rated the translations very harshly, with a full 20% judged as 'Nonsense/Wrong Language', with trusted native speakers confirming that the translations were unusable."
"What's happening here that the model translates into (a corrupted version of ) the wrong dialect, but it is close enough on a character n-gram level" for the automatic benchmark to score it high, they observe.
"This is the result of a data pollution problem," they deduce, "since these languages are so close to other much more common languages on the web […] the training data is much more likely to be mixed with either corrupted versions of the higher-resource language, or other varieties."
Examples of translations with correct terms in blue and mistranslations in yellow. The left-hand column shows the code for which language is being translated into, using the standard BCP-47 tags.
Bapna et al., 2022
Also: Google uses MLPerf competition to showcase performance on gigantic version of BERT language model
And then there are what the authors term "characteristic error modes" in translations, such as "translating nouns that occur in distributionally similar contexts in the training data," such as substituting "relatively common nouns like 'tiger' with another kind of animal word, they note, "showing that the model learned the distributional context in which this noun occurs, but was unable to acquire the exact mappings from one language to another with enough detail within this category."
Such a problem occurs with "animal names, colors, and times of day," and "was also an issue with adjectives, but we observed few such errors with verbs. Sometimes, words were translated into sentences that might be considered culturally analogous concepts – for example, translating "cheese and butter" into "curd and yogurt" when translating from Sanskrit."
Also: Google's latest language machine puts emphasis back on language
The authors make an extensive case for working closely with native speakers:
We stress that where possible, it is important to try to build relationships with native speakers and members of these communities, rather than simply interacting with them as crowd-workers at a distance. For this work, the authors reached out to members of as many communities as we could, having conversations with over 100 members of these communities, many of whom were active in this project.
An appendix offers gratitude to a long list of such native speakers.
Despite the failures cited, the authors conclude the work has successes of note. In particular, using the LangID approach to scour the web, "we are able to build a multilingual unlabeled text dataset containing over 1 million sentences for more than 200 languages and over 100 thousand sentences in more than 400 languages."
And the work with Transformer models convinces them that "it is possible to build high quality, practical MT models for long-tail languages utilizing the approach described in this work."
Scores for languages when translating from English and back to English again, correlated to how many sample sentences the language has. Toward the right side, higher numbers of example sentences result in better scores. There are outliers, such as English in Cyrillic, which has very few examples but translates well.
Bapna et al., 2022
What do you do after you have collected writing samples for a thousand languages for the purpose of translation, and humans still rate the resulting translations a fail?
Examine the failures, obviously.
And that is the interesting work that Google machine learning scientists related this month in a massive research paper on multi-lingual translation, "Building Machine Translation Systems for the Next Thousand Languages."
"Despite tremendous progress in low-resource machine translation, the number of languages for which widely-available, general-domain MT systems have been built has been limited to around 100, which is a small fraction of the over 7000+ languages that are spoken in the world today," write lead author Ankur Bapna and colleagues.
The paper describes a project to create a data set of over a thousand languages, including so-called low-resource languages, those that have very few documents to use as samples for training machine learning.
Also: DeepMind: Why is AI so good at language? It's something in language itself
While it is easy to collect billions of example sentences for English, and over a hundred million example sentences for Icelandic, for example, the language kalaallisut, spoken by about 56,000 people in Greenland, has fewer than a million, and the Kelantan-Pattani Malay language, spoken by about five million people in Malaysia and Thailand, has fewer than 10,000 example sentences readily available.
To compile a data set for machine translation for such low-resource languages, Bapna and two dozen colleagues first created a tool to scour the Internet and identify texts in low-resource languages. The authors use a number of machine learning techniques to extend a system called LangID, which comprises techniques for identifying whether a Web text belongs to a given language. That is a rather involved process of eliminating false positives.
After scouring the Web with LangID techniques, the the authors were able to assemble "a dataset with corpora for 1503 low-resource languages, ranging in size from one sentence (Mape) to 83 million sentences (Sabah Malay)."
The scientists boiled that list down to 1,057 languages "where we recovered more than 25,000 monolingual sentences (before deduplication)," and combined that group of samples with the much larger data for 83 "high-resource languages" such as English.
Also: AI: The pattern is not in the data, it's in the machine
They then tested their data set by running experiments to translate between the languages in that set. They used various versions of the ubiquitous Transformer neural net for language modeling. In order to test performance of translations, the authors focused on translating to and from English with 38 languages for which they obtained example true translations, including kalaallisut
That's where the most interesting part comes in. The authors asked human reviewers who are native speakers of low-resource languages to rate the quality of translations for 28 languages on a scale of zero to six, , with 0 being "nonsense or wrong language" and 6 perfect."
Also: Facebook open sources tower of Babel, Klingon not supported
The results are not great. Out of 28 languages translated from English, 13 were rated below 4 on the scale in terms of quality of translation. That would imply almost half of the English to target translations were mediocre.
The authors have a fascinating discussion starting on page 23 of what seems to have gone wrong in those translations with weak ratings.
"The biggest takeaway is that automatic metrics overestimate performance on related dialects," they write, meaning, scores the machine assigns to translations, such as the widely used BLEU score, tend to give credit where the neural network is simply translating into a wrong language that is like another language. For example, "Nigerian Pidgin (pcm), a dialect of English, had very high BLEU and CHRF scores, of around 35 and 60 respectively. However, humans rated the translations very harshly, with a full 20% judged as 'Nonsense/Wrong Language', with trusted native speakers confirming that the translations were unusable."
"What's happening here that the model translates into (a corrupted version of ) the wrong dialect, but it is close enough on a character n-gram level" for the automatic benchmark to score it high, they observe.
"This is the result of a data pollution problem," they deduce, "since these languages are so close to other much more common languages on the web […] the training data is much more likely to be mixed with either corrupted versions of the higher-resource language, or other varieties."
Examples of translations with correct terms in blue and mistranslations in yellow. The left-hand column shows the code for which language is being translated into, using the standard BCP-47 tags.
Bapna et al., 2022
Also: Google uses MLPerf competition to showcase performance on gigantic version of BERT language model
And then there are what the authors term "characteristic error modes" in translations, such as "translating nouns that occur in distributionally similar contexts in the training data," such as substituting "relatively common nouns like 'tiger' with another kind of animal word, they note, "showing that the model learned the distributional context in which this noun occurs, but was unable to acquire the exact mappings from one language to another with enough detail within this category."
Such a problem occurs with "animal names, colors, and times of day," and "was also an issue with adjectives, but we observed few such errors with verbs. Sometimes, words were translated into sentences that might be considered culturally analogous concepts – for example, translating "cheese and butter" into "curd and yogurt" when translating from Sanskrit."
Also: Google's latest language machine puts emphasis back on language
The authors make an extensive case for working closely with native speakers:
We stress that where possible, it is important to try to build relationships with native speakers and members of these communities, rather than simply interacting with them as crowd-workers at a distance. For this work, the authors reached out to members of as many communities as we could, having conversations with over 100 members of these communities, many of whom were active in this project.
An appendix offers gratitude to a long list of such native speakers.
Despite the failures cited, the authors conclude the work has successes of note. In particular, using the LangID approach to scour the web, "we are able to build a multilingual unlabeled text dataset containing over 1 million sentences for more than 200 languages and over 100 thousand sentences in more than 400 languages."
And the work with Transformer models convinces them that "it is possible to build high quality, practical MT models for long-tail languages utilizing the approach described in this work."
Sheree Miller has pretty much given up on American television. The 50-year-old stay-at-home mom spends about six hours a day sitting in her living room in La Vernia, Texas, in front of a large TV that’s never turned on. Instead, she’s busy working on her laptop as a volunteer for Rakuten Viki, a streaming service that adds subtitles to entertainment produced primarily in Asian countries. For over a decade, Miller has been part of the global community of unpaid users who translate video content on Viki into more than 150 languages. Viki declined to share an exact number, but Miller estimates that there are hundreds of thousands of people participating in the system; the 2015 book The Informal Media Economy put the number at more than 100,000. For their efforts, top contributors get a free Viki subscription. That’s all the compensation Miller says she needs: “The platform itself is for volunteers — those of us in obsession mode.”
Before Viki, overseas fans who wanted to watch subtitled Asian TV shows or films found themselves playing monthslong games of roulette with piracy sites. “It was just horrible, the wait,” Miller recalls. “Sometimes dramas would never get finished, or a website would be obliterated, and then you’d have to go looking around, trying to scrounge up another website to find the same drama.” Viki was born in 2007 as ViiKii.net, a project by three college students at Harvard and Stanford. The site’s name combined the words “video” and “Wiki,” reflecting a desire to translate videos using crowdsourced contributions. The founders didn’t invent the concept of community-powered subtitling — before high-speed internet existed, anime fans were trading “fansubs” on VHS tapes and laserdiscs — but they weren’t shy about wanting Viki to eventually become, according to a blog by co-founder Jiwon Moon in 2008, a new “grand cultural Silk Road.” Viki developed software that allowed multiple people to subtitle a project simultaneously, and in 2013, three years after its official launch, the company was acquired by Japanese e-commerce giant Rakuten for $200 million.
Today, the site once funded by donations from early users like Miller now offers two tiers of paid subscriptions as well as a limited free plan with ads. Much of Viki’s popular content hails from South Korea, including K-dramas What’s Wrong With Secretary Kim and Descendants of the Sun, reality programs like Queendom 2 and Running Man, and annual awards shows for music and acting. The platform also hosts titles from mainland China, Taiwan, and Japan, among several other countries, and since 2015, it has produced its own Viki Originals, including the viral Chinese series Go Go Squid! Viki survived even as major streamers such as Netflix and Amazon bid up the costs of licensing Asian content, which Variety reported was the reason for Warner Bros.’s 2018 shutdown of DramaFever, once Viki’s biggest competitor. By the end of 2021, Viki was serving 53 million users — many of whom want their new subtitled content now.
“Viewers of every language have something in common: They bitch, they complain,” says Connie Meredith, an 80-year-old contributor based in Honolulu, Hawaii. On Viki, an episode of a popular drama is typically translated into English, Viki’s base language for subsequent translations, within 24 to 48 hours of airing. Meredith says volunteers have been able to finish English subtitles as quickly as two to three hours. But less popular shows or shows that have complex dialogue take longer to be completed, and secondary language teams have to wait their turn for the English version. If you scroll through the ratings of any given title on Viki, you’ll see that the worst reviews overwhelmingly reference subtitling speed rather than the actual quality of the show or movie. Did the French translators go on vacation or what? Why am I paying for Viki if the Portuguese subtitles are never done on time? Meredith says reviewers frequently point out when translations are available on other sites before Viki. “And I’m thinking, Sure, you can get it with mistakes,” she says. “We are not in a race.”
In a sense, though, they are. The competition for international programming is only getting fiercer in the streaming-verse — and if Viki’s users aren’t getting the content they want at a speed they deem sufficient, they may look elsewhere. Yet Viki’s strategies to ratchet up subtitle production haven’t always sat well with an unpaid volunteer workforce that has wondered at times what, and who, the company actually values. “In experimenting to see what worked and what didn’t,” says Mariliam Semidey, 37, who served as Viki’s senior manager of customer and community experience from July 2016 to June 2021, “we might’ve made some mistakes.”
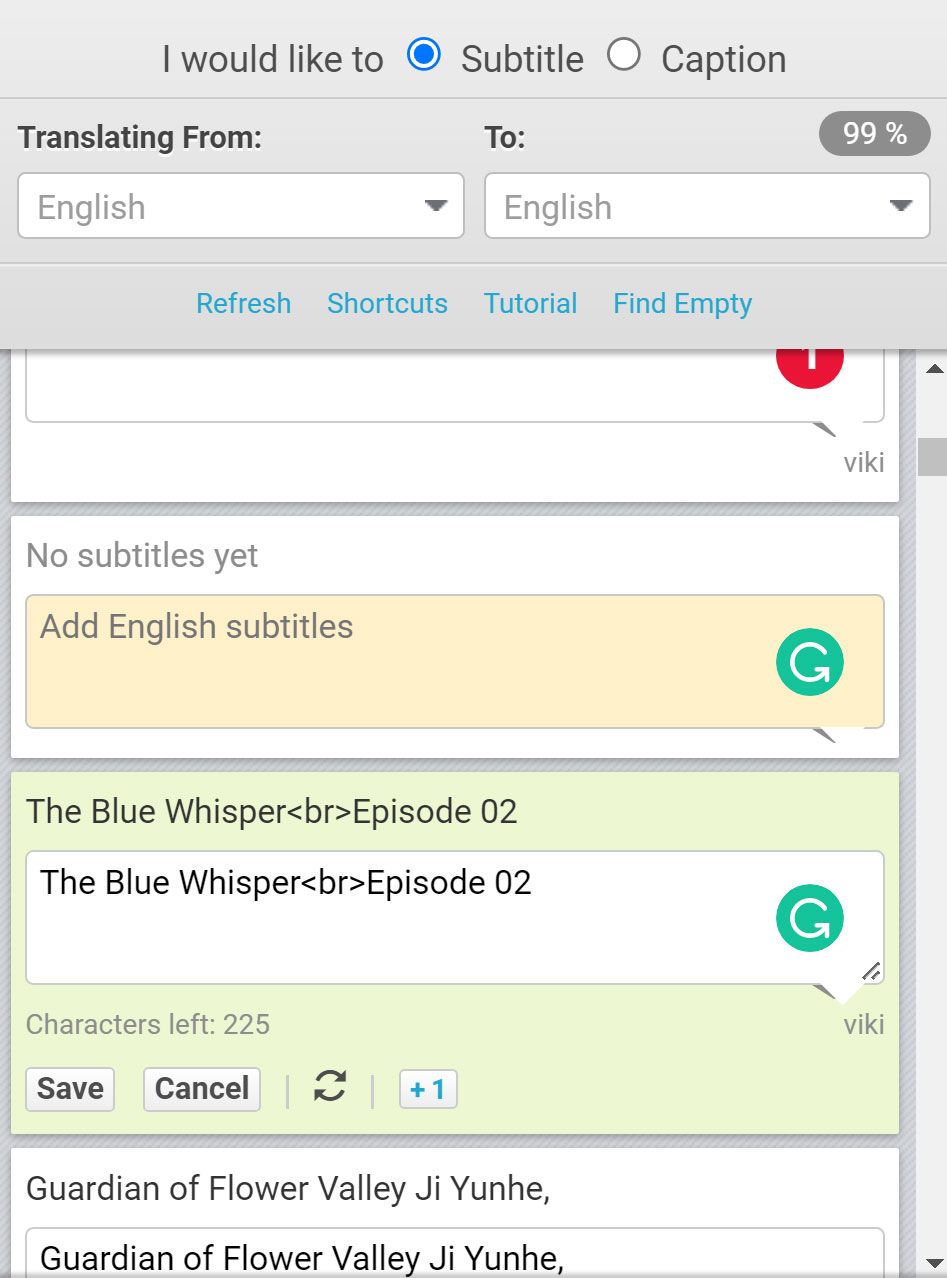
The subtitle editor, where Viki’s volunteers adjust the languages they are translating. Photo: Rakuten Viki
Time and time again while Semidey worked there, the question came up during corporate meetings: Should Viki get rid of its volunteers? But management always ultimately agreed that those contributors were too valuable because of the quality of their work. Over the years, Viki’s volunteers have developed their own training programs and standards for capturing cultural references, obscure idioms, and other tricky linguistic nuances. Their self-managed system involves several roles that don’t require fluency in multiple languages, although translation experience is also not necessary to become a subtitler. As a volunteer team lead, Meredith accepts subtitlers who do at least “a halfway decent job” on a short translation test she created. “The rule is don’t guess. If you don’t know the whole thing, skip it, and somebody else will fill it in,” says Meredith, who has taken Korean language courses through the University of Hawaii to improve her vocabulary. She might spend two hours hunting down a specific slang word or reaching out to friends with Ph.D.’s to determine the exact meaning of a phrase. Those efforts are representative of an ethos among the volunteers that has been present since the beginning: the understanding that good translations require time, effort, and teamwork.
“I think a lot of devoted volunteers feel the same way I do,” Meredith adds, “that we wouldn’t be here if it was a paid job because they can’t pay us enough for the time we spend.”
That’s why tension creeps in when volunteers get pushed to complete their contributions faster. Semidey says that when she was at Viki, any hour-long episode that volunteers took longer than eight hours to complete was considered “late” based on the speed of other streaming sites. If a team displayed a pattern of being too slow with their subtitles, Viki would speak up. Miller gets frustrated when Viki staffers reach out to tell her that volunteers should be moving faster. “Most of the people I know who contribute to Viki are not stay-at-home moms,” she says. “They have full-time jobs as nurses and techs and all kinds of things.” There are forms of compensation for contributors, starting with a free subscription to Viki, which is earned when a volunteer finishes 3,000 subtitles or segments (roughly equivalent to seven or eight episodes of work). From there, incentives are given to subtitlers who reach 20,000 contributions, rank high on Viki’s contribution leaderboard, or win volunteer-organized contests — in the past, such rewards have included tote bags, signed Psy CDs, and a Roku 3. Miller sees these perks as nice gestures of recognition. But as long as there’s no payment, it doesn’t sit right with her “to say to somebody that has a full-time job, ‘You better get your heinie here and sub this today at so-and-so time.’”
The dynamic Miller describes has contributed to the controversial efforts Viki has made to increase translation output over the years. In 2018, according to Semidey, Viki began using paid translators to speed up progress on select titles that weren’t expected to be popular, though Semidey says that the company sometimes made incorrect predictions and brought them in on shows that volunteers wanted for themselves. Nonetheless, she says, the decision resulted in a 50 to 60 percent decrease in customer complaints, though volunteers feel that it comes at the cost of quality: Often the subtitles they leave for last, such as the lyrics of official soundtracks (OSTs), require the most intricate translation work. “It’s like the difficulty of subtitling poetry,” says Meredith, who spearheaded the movement to start subbing OSTs on Viki in the first place. She estimates that the overwhelming majority of lines from paid translators “are wrongly subbed,” compelling volunteers to go back and make corrections.
The same goes for content that arrives on Viki with premade segments and subtitles. Beverley Johnson Wong, a 64-year-old contributor based in the Twin Cities, says it takes “at least double or triple the time” to correct errors compared to doing the work from scratch. She specializes in segmenting, which involves cutting videos into the clips that subtitlers fill in. Redoing short segments that cause text to disappear too quickly is tedious and doesn’t count toward contributions for Viki’s leaderboard, yet segmenters still clean up the mistakes. “We don’t want people thinking that was our work,” she explains, “because it was not done well.”
A waveform of the audio that Viki’s segmenters cut into parts. Photo: Rakuten Viki
Volunteer frustrations hit a flash point in September 2019, when Viki introduced a robot into its workforce. That month, hundreds of Viki volunteers went on strike because of the rollout of “Vikibot,” a collaborative project with the Rakuten Institute of Technology that used machine learning to automatically create segments and suggest subtitles. A form of AI called natural language processing also allowed it to learn from Viki’s large library of volunteer translations. The bot had already been implemented on inactive titles for a couple years, but Semidey says it was fed incorrect data and began overwriting existing subtitles in several languages. Outraged volunteers who felt that the machine’s work was subpar translated a strike notice into 12 languages. On Viki’s discussion board, one disgruntled user pointed out the site’s own ban on volunteers using automatic translation tools such as Google Translate: “Can I report Viki if they don’t follow the own guidelines they set?” Another warned, “Remember that we are the reason why Viki exists today as it is.”
Roughly a week later, Viki’s community team held a call to issue an apology and assure volunteers that future use of machine translation would be “as minimal as possible.” But the trust was broken, says Semidey. When Viki proposed a feature the following year that would allow viewers to opt to switch to a separate track of “auto-translated” subtitles, volunteers reacted negatively, stating that the decision would pressure them to rush to prevent viewers from settling for lower-quality translations. While the auto-subs feature was not officially implemented, current volunteers still identify external translations from paid translators and auto-subs as a persistent issue.
Semidey says that working at Viki was a constant struggle to balance the needs of volunteers with the wishes of customers who could threaten to cancel subscriptions. During her time at the company, she remembers having at most three staff members assigned to directly interact with its vast network of volunteers. She also saw several well-known contributors quit over conflicts with Viki staff or other volunteers. When she left in 2021, she felt there were many promises Viki failed to deliver on, including better project-management tools.
What Viki Volunteers Do
Every title is translated by a team of volunteers known as a “channel” and made up of several different roles.
1. Viki staff select a volunteer to be channel manager, responsible for overseeing progress and recruiting volunteers for other positions.
2. Moderators track new episode drops and let segmenters, subtitlers, and editors know when to start working.
3. Segmenters cut videos into parts the subtitlers translate into English. Three types of editors — translation, general, and chief — check for grammar, style, spelling, and overall quality.
4. Once English subtitles are done, subtitlers in other languages can begin.
“We understand that there are elements that can be improved within our Viki Contributor community, which is why we value their thorough and honest feedback,” Viki said in a statement from current community manager Sean Smith, noting that the company has “enhanced” project management and user-messaging features over time. “We’re actively engaged with a mixture of contributors to further improve tools and workflows.”
Meanwhile, Viki’s overall contributor numbers continue to grow. During the pandemic, volunteers had more free time to join Viki’s pool, leading to 22 percent year-over-year growth in subtitlers globally from 2020 to 2021, according to company data. In 2021, the average monthly contribution by Viki’s community of active subtitlers and segmenters increased by nearly 40 percent. Manuela Ogar Mraovic, who is currently topping the May community leaderboard, had only been subtitling on Viki for a couple months before taking the top spot in March. The retiree from Šibenik, Croatia, hasn’t dropped below second place since, and says she’s “really enjoying every second in this community, working and gaining knowledge.”
Some longtime contributors nevertheless have concerns about the platform’s sustainability, especially as Asian entertainment continues to gain international popularity and attract investment from large corporations like Netflix, Disney+, and Amazon Prime that don’t rely on volunteer-powered systems. One anonymous volunteer who was involved in the 2019 strike says they believe Viki’s volunteer community will inevitably “disappear” in the long term, noting that machine translation software is said to be improving in several key languages. “But we have dozens and dozens of other languages on Viki. That’s why they need us,” the volunteer adds. “For now, we are useful because we are better qualified in all the languages of the world.”