[unable to retrieve full-text content]
Matthew McConaughey believes a word should be removed from dictionary MyWabashValley.comWednesday, May 18, 2022
Matthew McConaughey believes a word should be removed from dictionary - KMID - Local 2 News - Dictionary
[unable to retrieve full-text content]
Matthew McConaughey believes a word should be removed from dictionary KMID - Local 2 NewsMatthew McConaughey believes a word should be removed from dictionary - WHNT News 19 - Dictionary
[unable to retrieve full-text content]
Matthew McConaughey believes a word should be removed from dictionary WHNT News 19Noobs Should Embrace This New PlayStation ‘Gamer Dictionary’ - Lifehacker - Dictionary

I strongly believe console and PC gaming is for everyone, but let’s be honest: the jargony way people talk about video games can make it difficult to get into the hobby.
Unless you’re enmeshed in the video game world, a sentence like “the latest patch nerfed HP scaling on end-game mobs but made aggro proc OP” will make zero sense, but lots of gamers talk that way all the time. And it’s hard to get into a new game when every guide, article, YouTube video, or in-game chat message is full of words you don’t understand, from “roguelike” to “metroidvania.”
Thankfully, the folks at PlayStation have recognized this issue and created a “Gamer Dictionary” to help noobs parse all that jargon. Definitely bookmark the dictionary if you’re a new player, or if you’re trying to help someone get into games for the first time.

The dictionary contains an alphabetical sorting of over 100 gaming-specific words, phrases, and acronyms, and they’re all surprisingly helpful, even if you aren’t a total beginner. Some include explanations of technical terms like “Hit Box,” “Judder,” and “I-Frames”; slang phrases such as “gank” or “noob”; and acronyms like “GPU,” “K/D,” “OP,” and more. There are also simple explanations for common video game genres, so you’ll know the difference between an ARPG, a CRPG, and a JRPG.
It’s nice to have a one-stop resource where you can learn what it means to “git gud” or memorize ABCs of the RPG genre, but the list is missing explanations for several popular subgenres with annoyingly obtuse names like the aforementioned “metroidvania,” “roguelike,” and “soulslike.” Luckily, we have a guide that can help demystify these unhelpful video game genre descriptors.
I hope PlayStation continues to add to its Gamer Dictionary, but it’s already a helpful and necessary resource and I’m glad it exists. Recent NPD estimates show that three out of every four people in the United States play video games of some kind. While these figures include mobile and casual gaming, more people than ever are also playing on consoles or PCs, which inevitably means more people will be curious enough to try bigger, more immersive, and more exciting video games for themselves, too.
I’m excited to see companies take steps to make console and PC gaming more approachable—whether that’s Sony’s new gamer dictionary, Microsoft’s commitment to accessibility options, or Nintendo’s ever-broadening appeal via games like Nintendo Switch Sports, Animal Crossing, and Ring Fit Adventure.
[GameSpot]
Monday, May 16, 2022
Rotary, Library Foundation give books, dictionaries to students - Long Beach Press Telegram - Dictionary

It was a good time to be a Long Beach preschooler or third-grader last week.
Long Beach Rotary continued its “Reading by Nine” program by delivering more than 2,000 books, giving one to each 3- and 4-year-old attending the 31 LBUSD Child Development Centers. It was the latest donation in a program that has provided more than 300,000 books and e-books to Long Beach students from preschool to third-grade.
And the Long Beach Public Library Foundation reached the 19th year of its Dictionary Days, announcing every third-grade student in the Long Beach Unified School District will receive a combined dictionary-thesaurus this year. The foundation has distributed more than 135,000 new dictionaries through the program.
A donation from the Farmers & Merchants Bank Foundation made this year’s dictionary donation possible.
A February report from the school district said that of the students returning to in-person classes — following pandemic-induced campus closures — 61% of elementary and 66% of middle school students were reading below grade level, according to the foundation.
“Third grade is an important year for students because it marks their transition from learning to read to reading to learn,” the foundation’s release says. “A dictionary/thesaurus is a crucial resource for many students who are struggling to keep up in school following a long period of distance learning.”
Long Beach Rotary’s “Reading By Nine” program relies on donations from members for funding. This year, the Literacy Committee led by Frank Newell and Nelinia Varenas, raised $84,000.
Te effort has raised nearly $900,000 over the years.
Besides buying books, the money is used for innovative teacher literacy grants, nonprofit early education and literacy programs, and community events supporting literacy.
Club members traditionally go to schools to read to children on book distribution day, and this year, they visited the Child Development Center at Burbank Elementary School.
“Being with all those wonderful children was ‘Chicken Soup for The Soul’,” club member Michael Rivard said after the event, “and gave me a happy heart the rest of the day.”
Sign up for The Localist, our daily email newsletter with handpicked stories relevant to where you live. Subscribe here.
Sunday, May 15, 2022
PlayStation Has Compiled a Handy Dictionary of Gaming Terms and Slang - PlayStation LifeStyle - Dictionary
Forget your Cambridge, Oxford, and Urban dictionaries because we now have the ultimate PlayStation gaming dictionary compiled by none other than Sony for gamers who aren’t familiar with the “most popular words, terminology, and slang phrases” used by fellow cool kids. As spotted by Reddit user xektor, the dictionary seems to be a new addition to PlayStation’s website and is called “PlayStation Ultimate Gaming Glossary.”
PlayStation gaming dictionary is actually pretty handy

On a serious note, the dictionary is pretty handy as there are terms even I’m not familiar with and I’ve been playing games for far longer than I like to admit (anyone else here had a Sinclair ZX Spectrum or Atari?) but it also makes for a fun read. Here are some of my personal favorites, although these are commonly-used terms:
Git gud – A deliberate misspelling of ‘Get Good’, ‘git gud’ is an injunction to raise one’s own skill level in response to a particularly difficult challenge. Players complaining of unreasonable difficulty in a game are often encouraged to ‘git gud’, persevering with the game and overcoming the challenge through patience and learning.
Noob-tube – Originally referring to grenade launchers, a ‘noob-tube’ typically refers to powerful, easy-to-use weapons that are popular with inexperienced players, particularly in competitive multiplayer.
Wrecked – Often stylised as ‘rekt’ or ‘recked’, to be wrecked or to wreck another is to best or be bested easily, typically in a one-on-one encounter. ‘Get Rekt’ is a common victory put-down when overcoming a difficult or tenacious enemy.
For those wondering, I ripped that image above featuring FromSoftware bosses from a PlayStation Blog post where game developers discuss their favorite FromSoftware bosses. I felt like it went well with the “git gud” theme.
Anyway, check out the full dictionary here (thanks, Reddit).
In other news, military shooter series Arma looks set to make its console debut, and it looks like we’re about to get some major Final Fantasy news.
Saturday, May 14, 2022
Google Translate Utilize Zero-Resource Machine Translation To Support New Languages - MarkTechPost - Translation
This Article Is Based On The Research Paper 'BUILDING MACHINE TRANSLATION SYSTEMS FOR THE NEXT THOUSAND LANGUAGES'. All Credit For This Research Goes To The Researchers 👏👏👏 Please Don't Forget To Join Our ML Subreddit
Machine translation (MT) technology has advanced significantly. The quality of translation services has increased, and they have grown to incorporate new languages, according to research benchmarks such as WMT. Even though existing translation services cover languages spoken by most people throughout the world, they only cover about 100 languages, accounting for slightly over 1% of all languages spoken globally. Furthermore, the covered languages are predominantly European, generally ignoring linguistically diverse regions such as Africa and the Americas.
Building functional translation models for the long tail of languages face two major roadblocks. The first is data scarcity; digitized material for many languages is scarce, and finding it on the web can be difficult due to quality concerns with Language Identification (LangID) models. With monolingual data collected from the web, the next issue is to develop high-quality, general-domain MT models from small amounts of monolingual training data. They use a pragmatic approach, leveraging all parallel data available for higher resource languages to improve the quality of long-tail languages with only monolingual. They call this setting zero-resource because no direct supervision is known for our long-tail languages. The second issue emerges as a result of modeling restrictions. Without such data, models must learn to translate from small amounts of monolingual text, a new area of research. These issues must be addressed for translation models to achieve adequate quality. In “Building Machine Translation Systems for the Next Thousand Languages,” they describe how to create high-quality monolingual datasets for over a thousand languages that lack translation and train MT models using monolingual data alone. They expanded Google Translate to add 24 under-resourced languages as part of this work. They developed and utilized specific neural language identification models and unique filtering procedures to build monolingual datasets for these languages. The strategies they provide supplement massively multilingual models with a self-supervised job to enable zero-resource translation. Finally, let’s discuss how native speakers assisted us in achieving this goal.
Meet the Data

It’s far more complex than it appears to automatically collect useful textual data for under-resourced languages. Many publicly available datasets crawled from the web typically include more noise than usable data for the languages they seek to cover. Tasks like LangID, which work well for high-resource languages, fail for low-resource languages. They discovered that the dataset was too noisy to be helpful in our early attempts to identify under-resourced languages on the web by training a typical Compact Language Detector v3 (CLD3) LangID model.
They trained a Transformer-based, semi-supervised LangID model on over 1000 languages as an alternative. This model combines the LangID job with the MAsked Sequence-to-Sequence (MASS) task to generalize across noisy online data. MASS essentially mutilates the input by deleting token sequences at random and then training the model to predict these sequences. They used a dataset filtered with a CLD3 model and trained to recognize clusters of comparable languages to apply the Transformer-based model. Then used, the open-source Term Frequency-Inverse Internet Frequency (TF-IIF) filtering to locate and delete sentences in related high-resource languages and construct a range of language-specific filters to exclude certain diseases. The end result was a dataset of monolingual text in over 1000 languages, with over 100,000 phrases in 400 of them. They conducted human evaluations on 68 of these languages and discovered that the vast majority (>70%) reflected high-quality, in-language information.
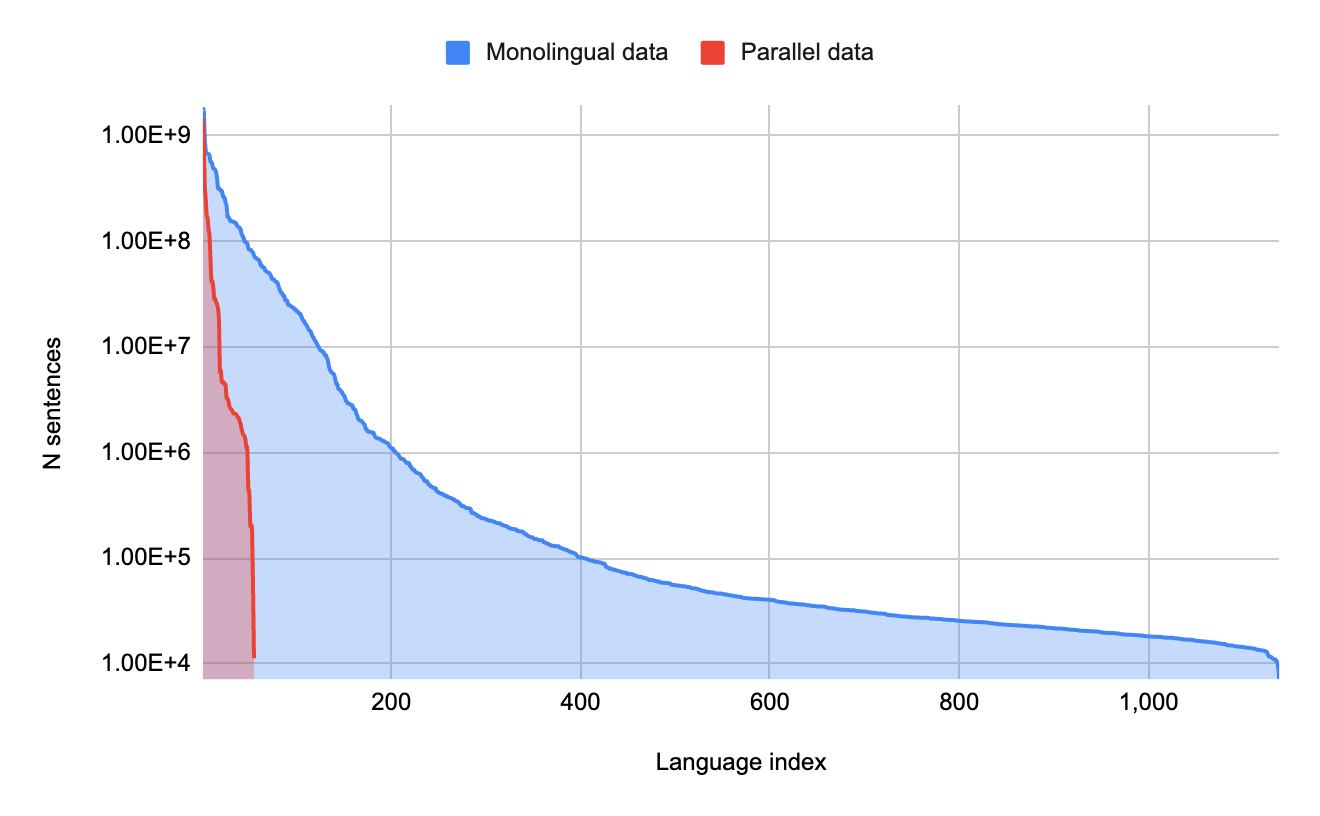
1000 languages web-crawled datasets: The absence of digitized and accessible information and NLP tools like language identification (LangID) models has hampered progress in developing machine translation systems in these languages. Such resources are abundant for higher education.
Meet the Models
They devised a simple yet practical approach for zero-resource translation, i.e., translation for languages with no in-language parallel text and no language-specific translation examples, after we obtained a collection of monolingual text in over 1000 languages.
They integrate all accessible parallel text data with millions of instances for higher resource languages to enable the model to learn the translation task rather than limiting it to an artificial scenario with only monolingual text. Using the MASS challenge, they simultaneously train the model to learn representations of under-resourced languages directly from the monolingual text. To complete this objective, the model must construct a comprehensive presentation of the language in issue and a detailed knowledge of how words interact with each other in a sentence.
Any input the model sees during training has a particular token specifying which language the output should be in, much like the typical multilingual translation formulation. The use of the exact unique tickets for both the monolingual MASS job and the translation task is an additional innovation. As a result, the token to french may signal that the source is in English and has to be translated to French (the translation assignment) or that the reference is in garbled French and requires fluent translation (the MASS task). A translation to a french tag takes on the meaning “Produce a fluent output in French that is semantically near to the input,” regardless of whether the input is garbled in the same language or in a different language entirely, by employing the same tags for both jobs. There isn’t much of a distinction between the two from the model’s standpoint.
Surprisingly, this straightforward approach yields excellent zero-shot translations. The resulting model’s BLEU and ChrF scores are in the 10–40 and 20–60 ranges, indicating mid- to high-quality translation.These metrics, however, were only computed on a tiny portion of languages with human-translated evaluation sets. They developed evaluation criteria based on round-trip translation to better evaluate the quality of translation for the remaining languages. We were able to see that several hundred languages are nearing high translation quality.
They use the model to generate vast amounts of synthetic parallel data, filter the data using round-trip translation, and train the model on this filtered synthetic data using back-translation and self-training. Finally, we refine the model on a subset of 30 languages before distilling it into a model that can be served
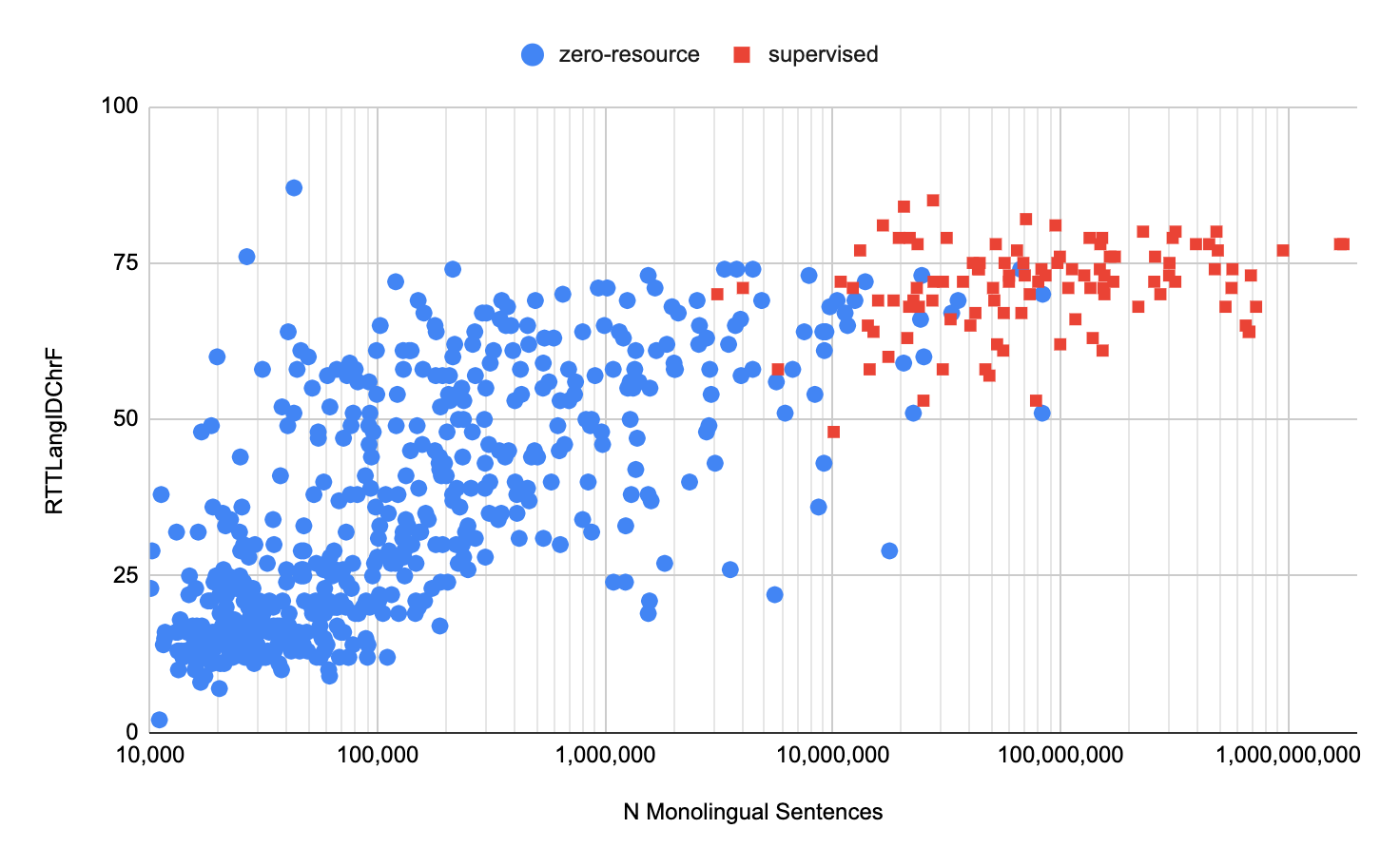
.
Native Speakers’ Contributions
Research required regular communication with native speakers of these languages. They worked with approximately 100 people from Google and other organizations who were fluent in these languages. Some volunteers assisted in developing specific filters to remove text that was not recognized by automatic methods, such as Hindi combined with Sanskrit. Others helped with transliteration between different scripts used by the languages, such as Meetei Mayek and Bengali, for which adequate tools were not available. In contrast, still, others assisted with a variety of evaluative chores.
Final Thoughts
Native speakers were also crucial in advising on aspects of political sensitivity, such as the proper name for the language and the writing system to adopt.
This is a significant first step in supporting more language technologies in languages with limited resources. Most significantly, we want to emphasize that the quality of translations produced by these models is still far inferior to that of Google Translate’s higher-resource languages. These models are a good starting point for interpreting information in under-resourced languages, but they will make mistakes and have biases. The output should be carefully considered, as with any ML-driven tool.
Source: https://ift.tt/P3aFJsM
Paper: https://ift.tt/a68THUZ
Subscribe to:
Posts (Atom)